Il est nécessaire de prendre son temps pour suivre l’intégralité de cette procédure qui a été découpée en plusieurs étapes et pouvant être exécutées sur plusieurs jours…
Contexte
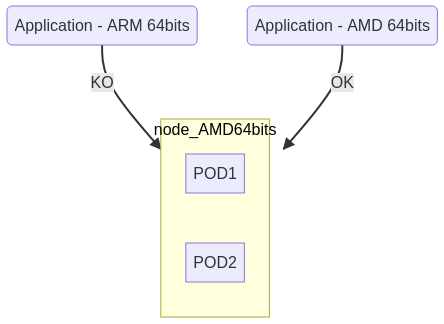
MytinyDC fonctionne sur une architecture de type ARM : armhf (32bits) et aarch64 (64 bits). La fondation RaspberryPI a mis à disposition une version beta de RaspiOS 64Bits, j’abandonne par conséquent Raspbian et RaspiOS 32bits.
“Kubernetes” est censé supporter la mixité des architectures CPU, un de mes objectifs est de permettre l’ajout momentanné de nodes plus puissantes que celles utilisés au quotidien, Ce POC va donc intégrer des CPUs de type AMD64, et ARM 64 bits
Cette toplogie, dite hybride, ne fonctionne que si les images “Docker” sont disponibles dans le format supporté par la CPU de la node. Si votre cluster est constitué d’unités “aarch64” et que vous souhaitez utiliser une application “Dockerisé” au format “amd64”, il est évident que ceci ne fonctionnera pas. Vous verrez que cette attention doit être portée à tous les niveaux de cette installation, puisque Kubernetes est exécuté dans des containers “Docker”.
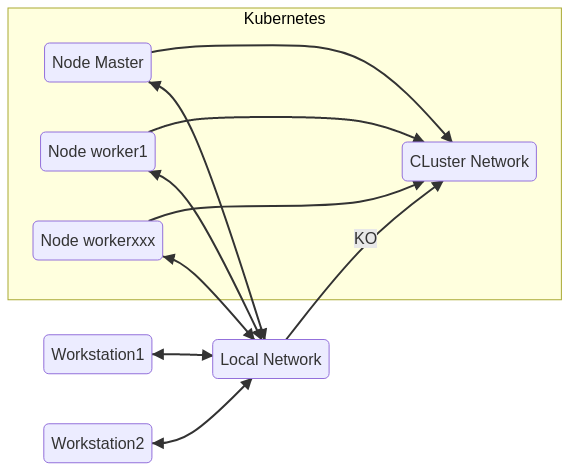
L’installation d’un Cluster “Kubernetes” nécessite un miminum de deux unités de calcul, appelée “nodes” (serveurs physiques ou virtuels), une node de type “Master”, et une node de type “Worker”. Le “Master” sert à gérer le cluster, les “Workers” exécutent les applications. Si le “Master” tombe, les “Workers” continuent de fonctionner dans leur état, mais l’état global du Cluster ne sera plus disponible. Si un changement apparaît au niveau des “Workers”, le “Master” étant stoppé, les autres “Workers” n’en auront plus connaissance.
Une autre chose importante, “Kubernetes” fonctionne sur un réseau privé propre au Cluster et inaccessible des machines qui ne sont pas intégrées au Cluster. Vous pourrez avoir accès au service ssh des nodes mais pas au réseau privé du Cluster. Chaque node du cluster a accès aux autres nodes du cluster.
NB : Les shells proposés dans cette instruction sont écrits en Bash et généré par l’outil MytinyDC-automation.
Unités centrales pour ce POC
- 1 node “Master”, rock64 (4Gb RAM - Ethernet Gigabit) - Debian10/aarch64 (64bits)
- 2 nodes “Worker”, machines virtuelle Virtualbox (2Gb RAM - Ethernet Gigabit) - Debian10/amd64 (64bits)
- 1 node “Worker”, RaspberryPi3 Minimum (1Gb RAM - Ethernet 100Mbps) - RaspiOS 64 Bits/aarch64 (64 bits - les composants Kubernetes pour ARM sont le plus souvent disponibles en 64 bits).
- 1 console SSH pour accéder à ces machines.
Préparation des unités centrales
Installer sur chacune des unités, Debian10 : Suivre la procédure concernant l’installation des systèmes d’exploitation.
Après installation il est très important :
- d’activer “Linux host bridge”
- d’activer le “forward network”
- d’activer la notion de “cgroup” et de désactiver le swap,
Activer “Linux host bridge”
## bridge-nf-call
sysctl -w net.bridge.bridge-nf-call-ip6tables=1
sysctl -w net.bridge.bridge-nf-call-iptables=1
Activer le “forward network”
sysctl -w net.ipv4.ip_forward=1
Activation de la notion “cgroup” et désactivation du swap
Architecture Amd64
Editer le fichier “/etc/fstab”
# Commentez la ligne contenant le mot "swap"
# Exemple : UUID=7dd7bd28-a2e6-4ec9-87a8-af40ae6a0459 none swap sw 0 0
# Devient :
#UUID=7dd7bd28-a2e6-4ec9-87a8-af40ae6a0459 none swap sw 0 0
Enregistrez puis exécuter :
swapoff -a
## Ou rebooter l'unité
Les cgroups sont activés par défaut sur ce type de plateforme.
Architecture ArmBian (Rock64)
Editez le fichier “/etc/default/armbian-zram-config” :
#remplacer la ligne ENABLED=TRUE
#par
ENABLE=FALSE
Puis Exécutez
swapoff -a
## Ou rebooter l'unité
Les cgroups sont activés par défaut sur ArmBian.
Architecture RaspiOS - 64 Bits (RaspberryPi)
dphys-swapfile swapoff
dphys-swapfile uninstall
update-rc.d dphys-swapfile remove
apt-get -y purge dphys-swapfile
Pour activer les “cgroups”
sed -i '$ s/$/ cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1 swapaccount=1/' /boot/cmdline.txt
rebooter l’unité.
Installation d’une node de type “Master”
Ceci nécessite un serveur prêt à l’emploi (connexion réseau local, accès internet, accès ssh) et paramétré comme indiqué précédemment.
Vous trouverez ici un exemple de shell permettant l’installation d’une node “Master” :
Téléchargez le shell d’installation node Master
Se connecter “root " au serveur destiné à devenir le “Master” dans votre cluster “Kubernetes” (la notion de haute disponibilité, multi-Master n’est pas abordée ici).
wget https://www.mytinydc.com/dl/mytinydc_kubernetes_install_node_master.sh
chmod +x mytinydc_kubernetes_install_node_master.sh
# Consulter le shell
cat ./mytinydc_kubernetes_install_node_master.sh
# Exécuter le shell - supprimer la marque de commentaire
# ./mytinydc_kubernetes_install_node_master.sh
En fin d’installation, le shell indique la commande à exécuter sur chaque node de type “Worker”, afin de les faire “rejoindre” le cluster. Il est inutile d’en garder un copie. Nous verrons plus loin, comment générer une nouvelle commande de ce type.
Installation du CNI (Container Network Interface)
Ce composant réseau est nécessaire au fonctionnement de “Kubernetes” (Voir ici)
J’en ai essayé plusieurs et c’est “flannel” que j’ai choisi : il est populaire, facile à installer, suppporté par les CPU de type ARM. Flannel c’est ici : (https://github.com/coreos/flannel).
Le CNI s’installe sur le node Master avec la commande :
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Téléchargez le shell d’installation du CNI Flannel pour le node Master
wget https://www.mytinydc.com/dl/mytinydc_kubernetes_install_cni_flanner.sh
chmod +x mytinydc_kubernetes_install_cni_flanner.sh
# Consulter le shell
cat ./mytinydc_kubernetes_install_cni_flanner.sh
# Exécuter le shell - supprimer la marque de commentaire
#./mytinydc_kubernetes_install_cni_flanner.sh
NB : La node Master se charge de “distribuer” le plugin réseau aux nodes “Worker”, lorsque celles-ci rejoignent le Cluster. Dans le cadre d’un environnement hybride au niveau de l’architecture CPU des nodes “Worker”, il est important de choisir un CNI supporté par les plateformes qui rejoindront le Cluster.
Ajouter une Node de type “Worker”
Ajouter une node au cluster est relativement simple, il faut préparer un serveur, puisqu’une node est un serveur (virtuel ou physique) comme indiqué en première partie, puis exécuter un ensemble d’instructions :
- installation des paquets Debian nécessaire
- commande permettant de rejoindre le cluster. Avant toute chose, il faut générer les autorisations permettant à une node de joindre le cluster, ceci s’opère sur le master. L’exécution de cette commande permettra d’obtenir la commande à exécuter sur les nodes “Worker” afin que ces dernières soient autorisées à rejoindre le cluster. Sur la master :
kubeadm token create --print-join-command
Vous obtenez ce type de résultat:
kubeadm join 192.168.0.33:6443 --token 709pj7.h1e4x7z06eolg8h8 --discovery-token-ca-cert-hash sha256:668fa27ba6967f6613aa7aea8a60a120461eb0f9a17285ac1900f1a4395494ce
Sur la node Worker : Vous pouvez exécutez ce script : Téléchargez le shell d’installation d’une node Worker
wget https://www.mytinydc.com/dl/mytinydc_kubernetes_install_node_worker.sh
chmod +x mytinydc_kubernetes_install_node_worker.sh
# Consulter le shell
cat ./mytinydc_kubernetes_install_node_worker.sh
## Attention le paramètres doit être indiqué entre double-quote ""
# Exécuter le shell - supprimer la marque de commentaire
#./mytinydc_kubernetes_install_node_worker.sh "[Résultat de la commande kubeadm exécutée sur le master]"
Patientez durant l’intallation, une fois terminée, rendez-vous sur le Master et exécutez kubectl get nodes, la nouvelle node doit apparaître et “Ready”.
Contrôles post-installation
Contrôle des nodes
Le “Master” est installé et prêt, tapez la commande kubectl get nodes -o wide, vérifiez bien que l’adresse IP (colonne “EXTERNAL-IP”) correspond bien à l’adresse IP du serveur sur le réseau local.
Exemple, si votre serveur de type “Master” est joignable du réseau avec l’adresse IP “192.168.0.38”, la colonne “EXTERNAL-IP” doit indiquer cette valeur :
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
debian1 Ready <none> 4d11h v1.19.2 192.168.0.39 <none> Debian GNU/Linux 10 (buster) 4.19.0-10-amd64 docker://18.9.1
rock64 Ready master 4d11h v1.19.2 192.168.0.38 <none> Armbian 20.08.3 Buster 4.4.213-rockchip64 docker://18.9.1
Si ce n’est pas le cas, vous obtenez par exemple :
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
debian1 Ready <none> 4d11h v1.19.2 172.17.0.1 <none> Debian GNU/Linux 10 (buster) 4.19.0-10-amd64 docker://18.9.1
rock64 Ready master 4d11h v1.19.2 172.17.0.1 <none> Armbian 20.08.3 Buster 4.4.213-rockchip64 docker://18.9.1
r
Remarquez que l’adresse de chaque node (colonne “EXTERNAL-IP”) indique 172.17.0.1, il apparaît que le plugin flannel “s’emmêlent” quand il existe plusieurs interfaces réseaux, ce qui est le cas avec les machines virtuelles (réseau local, bridges docker, etc…).
Pour corriger ce problème, éditez le fichier “/etc/hosts” de chaque node en y indiquant le nom de la node et son ip réelle. Exemple avec “debian1” :
vi /etc/hosts
Suprimer la ligne 127.0.1.1 debian1 et ajoutez la ligne :
192.168.0.39 debian1
et faire la même chose sur chacune des nodes, en adaptant avec la configuration réseau de la node.
Une fois l’opération effectuée sur chaque node, supprimer les pods relatifs à “flannel”, Exemple : kubectl delete pod -n kube-system kube-flannel-ds-fflvz. Pour obtenir la liste de ces pods :
kc get pod -A | grep kube-flannel
Les pods seront recréés automatiquement par “Kubernetes” et correctement configurés cette fois. Vérifier avec la commande kubectl get nodes -o wide.
Contrôle du fonctionnement global
A ce stade, il est important de contrôler l’état du réseau du cluster, le réseau est primordial. Si le réseau est instable, votre cluster ne fonctionnera pas.
Contrôle des processus
Ce shell permet de vérifier, sur la node “Master” que tous les processus nécessaires fonctionnent.
Téléchargez le shell de test des processus
A partir de la node “Master” :
wget https://www.mytinydc.com/dl/mytinydc_kubernetes_processus_test.sh
chmod +x mytinydc_kubernetes_processus_test.sh
# Consulter le shell
cat ./mytinydc_kubernetes_processus_test.sh
# Exécuter le shell - supprimer la marque de commentaire
#./mytinydc_kubernetes_processus_test.sh
Contrôle des endpoints
Ce shell permet de vérifier le fonctionnement minimal des endpoints disponibles.
Téléchargez le shell de test des endpoints
A partir de la node “Master” :
wget https://www.mytinydc.com/dl/mytinydc_kubernetes_ping_test_endpoints.sh
chmod +x mytinydc_kubernetes_ping_test_endpoints.sh
# Consulter le shell
cat ./mytinydc_kubernetes_ping_test_endpoints.sh
# Exécuter le shell - supprimer la marque de commentaire
#./mytinydc_kubernetes_ping_test_endpoints.sh
Contrôle du DNS interne
Ce shell permet de vérifier le fonctionnement minimal du DNS interne “Kubernetes”.
Téléchargez le shell de test du DNS interne
A partir de la node “Master” :
wget https://www.mytinydc.com/dl/mytinydc_kubernetes_dns_test.sh
chmod +x mytinydc_kubernetes_dns_test.sh
# Consulter le shell
cat ./mytinydc_kubernetes_dns_test.sh
# Exécuter le shell - supprimer la marque de commentaire
#./mytinydc_kubernetes_dns_test.sh
Outils d’administration
Votre aliée de tous les jours : la commande “kubectl”.
Le nom de cette commande est un peu trop long à mon goût, j’ai donc créé un alias de commande nommée “kc”. Un alias de commande sous Linux est souvent le nom raccourci d’une commande fréquemment utilisée par un sysadmin. Sous Linux un alias se déclare ainsi :
alias kc=/usr/bin/kubectl
Pour personnaliser vous pouvez utiliser une variable comme suit :
# Alias kubectl (selon votre choix, pour moi c'est kc)
ALIASKUBECTL="kc"
alias $ALIASKUBECTL=/usr/bin/kubectl
Pour rendre cette personnalisation persistente, il faut ajouter ces commandes à votre fichier “.bashrc” situé dans la “home directory” de l’utilisateur Linux.
Une autre fonctionnalité plus qu’interressante, la completion automatique “Kubernetes”. L’implémentation est livrée dans le package “Kubernetes” : kubectl completion bash. L’exécution de cette commande indique toute les commandes de configuration nécessaires à “bash” pour obtenir une completion automatique.
Rendons l’ensemble persistant, cette opération va consister à définir l’alias de “kubeclt” et intégrer la completion automatique à chaque connexion de l’administrateur kubernetes à la console du “master” (vous pouvez personnaliser l’alias) :
# Controle arbitraire si exite déjà dans le fichier ~/.bashrc
grep -e "kubectl completion bash" ~/.bashrc
if [ "$?" == "1" ];then
cat <<EOT >> ~/.bashrc
###>>> Configuration pour Kubernetes
# Alias kubectl (selon votre choix, pour moi c'est kc)
ALIASKUBECTL="kc"
alias \$ALIASKUBECTL=/usr/bin/kubectl
# Intégration completion bash
source <(kubectl completion bash)
# Ajout des règle de complétion à mon alias
if [[ $(type -t compopt) = "builtin" ]]; then
complete -o default -F __start_kubectl \$ALIASKUBECTL
else
complete -o default -o nospace -F __start_kubectl \$ALIASKUBECTL
fi
###<<<
EOT
fi
Et pour travailler - Kubernetes - Cheatsheet
Installation d’une application de vérification de fonctionnement Docker
Pour vérifier que le système de déploiement et de service fonctionne correctement, nous allons déployer notre première application, très simple, un serveur nginx qui renvoit sa page par défaut.
Namespace
Les “namespaces” sont à l’image des tiroirs d’un meuble de rangement, chaque chose à sa place… Si vous ne spécifiez pas de namespace, le déploiement sera automatiquement “rangé” dans le “namespace” fourre-tout, nommé “default”.
Créons le namespace “kube-verify”
kubectl create namespace "kube-verify"
PS : Vous pouvez aussi utiliser le raccourci “ns” pour l’objet “namespace”, ex: kubectl create ns “kube-verify”
Déploiement
Connectez-vous à la node “Master”, puis créer le fichier “deployment-nginx-kubeverify.yaml” avec ce contenu :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: kube-verify
spec:
strategy:
type: Recreate
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Cette description permet d’installer le container ngnix sur les nodes “Worker”, ce déploiement sera “rangé” dans le namespace “kube-verify”.
Enregistrez puis exécuter la commande :
kubectl apply -f deployment-nginx-kubeverify.yaml
Dans cet situation, le cluster est capable de maintenir, en continu, une instance de nginx, c’est-à-dire démarrer un pod constitué, dans ce cas, d’un container permettant l’exécution du serveur web “nginx”.
Le déploiement est effectué on vérifie avec :
kubectl get deployment -n kube-verify
PS : Le raccourci pour l’objet “deployment” est “deploy”, ex : kubectl get deploy -n kube-verify
Cette commande liste tous les deploiements situés dans le namespace “kube-verify”
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 70m
On a bien un deploiement nommé “nginx” comme décrit dans le fichier yaml d’installation, et il existe un pod (1/1) démarré sur une instance demandée (notion de replicas). Pour obtenir la description complète du pod démarré et lié à ce déploiement, exécuter la commande :
kubectl get pods -n kube-verify
PS : Le raccourci pour l’objet “pods” est “pod”, ex : kc get pod -n kube-verify
vous obtenez un résultat de la sorte :
NAME READY STATUS RESTARTS AGE
nginx-7848d4b86f-jlkzk 1/1 Running 0 75m
Remarquez que le pod contient le nom du deploiement ainsi qu’un id unique.
Le pod “tourne”, mais nginx n’est pas exposé dans le cluster. L’exposition “réseau” d’une application se fait au moyen d’un service. Pour obtenir la liste de services :
kubectl get services -A
l’option “-A” permet d’inspecter tous les “namespaces”.
PS : Le raccourci pour l’objet “services” est “svc”, ex : kubectl get svc -A
Vous obtenez ce type de résultat :
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 16h
Il n’existe aucun service pour nginx donc joignable de nulle part. Exposons notre service (d’une manière très simpliste) :
kubectl expose deploy nginx -n kube-verify
rappelons la commande qui liste les services exposés :
kubectl get svc -A
Vous obtenez de genre de résultat :
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 16h
kube-verify nginx ClusterIP 10.109.211.116 <none> 80/TCP 2s
Vérifions maintenant l’accès à nginx, on voit qu’il est exposé sur l’ip 10.109.211.116 et le port 80/TCP, essayons avec la commande “curl”
curl 10.109.211.116:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Le service fonctionne correctement, nous arrivons sur la page nginx par défaut.
Notez bien que l’exposition n’est accessible que de l’ensemble du Cluster, c’ést-à-dire, des machines constituant le Cluster.
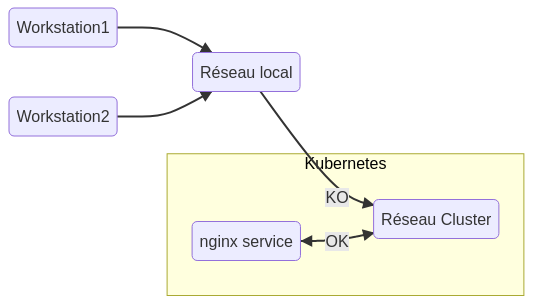
Les pods applicatifs sont exécutés sur les nodes de type “Worker”, ce sont ces nodes qui permettent une exposition plus large des services. Pour exposer un service au niveau de la node, donc accessible du réseau auquel elle appartient, vous devez spécifier le type “NodePort” lors de la création du service, par défaut, l’exposition est de type “ClusterIP”. (Un tuto parmis tant d’autres sur les expositions de services)
Exposons le service nginx au niveau de la node :
# Suppression du service
kubectl delete svc nginx -n kube-verify
# Création type NodePort
kubectl expose deploy nginx -n kube-verify --type=NodePort
Voyons le résultat :
kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17h
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 17h
kube-verify nginx NodePort 10.109.158.59 <none> 80:32020/TCP 61s
Le service nginx est exposé :
- Pour le cluster sur : 10.109.158.59:80
- Mais aussi sur le port 32020 de la node, ou des nodes (cas de haute disponibilité), sur lesquelles l’application “nginx” est exécutée.
On va donc chercher sur quelle node le pod “nginx” est exécuté, on sait que l’application est situé dans le namespace “kube-verify”, et je vais demander un affichage “large” des informations :
kubectl get pod -n kube-verify -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7848d4b86f-jlkzk 1/1 Running 0 138m 10.244.3.2 debian3 <none> <none>
Je vois que le pod est exécuté sur la node “debian3”, j’exécute la commande curl en indiquant le nom de la node ou bien son ip et le port défini par le service (32020 dans mon cas) :
curl debian3:32020
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
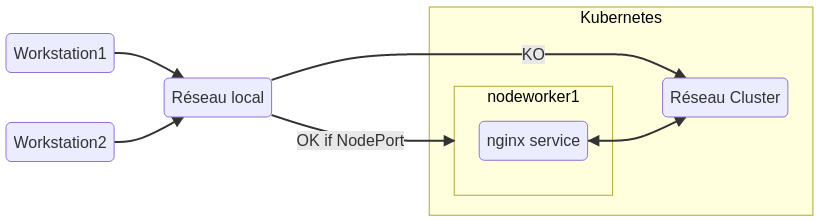
Notre service nginx est maintenant accessible de notre réseau local, donc facilement exposable sur internet via un reverse-proxy de type nginx ou haproxy.
Vous devrez indiquer en backend, la liste de toutes les nodes du cluster, puis le port du service. Le reverse proxy se chargera de détecter quelle node est, ou n’est pas accessible. Le reverse-proxy effectuera la redirection automatiquement.
Suppression du service kube-verify
# Suppression du service
kubectl delete svc nginx -n kube-verify
# Suppression du namespace - veuillez patienter quelques secondes
kubectl delete namespace "kube-verify"
Désinstaller Kubernetes (pour infos)
A opérer sur chaque noeud :
wget https://www.mytinydc.com/dl/mytinydc_kubernetes_uninstall.sh
chmod +x mytinydc_kubernetes_unistall.sh
# Consulter le shell
cat ./mytinydc_kubernetes_unistall.sh
# Exécuter le shell - supprimer la marque de commentaire
#./mytinydc_kubernetes_unistall.sh
Téléchargez le shell de desinstallation Kubernetes
Problèmes rencontrés
| Symptômes | action |
|---|---|
| Kubelet ne démarre pas sur une ou plusieurs nodes | Desactiver le swap |
| Erreur à l’installation error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR SystemVerification]: missing required cgroups: memory | activer les “cgroups” |
Conclusion
“Kubernetes”… Vous vous demandez toujours à quoi çà sert ?
Cette première approche permet de démontrer que le processus de démarrage d’une application, au sein du cluster, est décrit dans un seul fichier : l’image à installer, le port réseau à exposer. En continuant, vous découvrirez que l’on peut ajouter un espace de stockage partagé, une configuration partagée…
Avec ces notions il est facile de comprendre qu’une fois décrite, notre application peut être instanciée plusieurs fois avec les mêmes réglages et ce, sans intervention particulière.
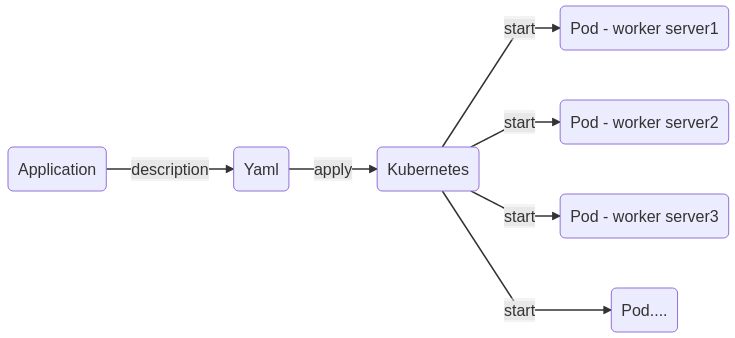
Notez bien que “Kubernetes” a été dessiné par, et pour des fournisseurs de Cloud. Ces derniers ont dû trouver une solution pour répondre aux demandes incessantes de mise à dispositions de containers et ont cherché un moyen de rationnaliser le processus de disponibilité d’une application. Cela peut paraître obscur d’un premier abord, mais vous allez très vite vous familiariser avec le concept.
Gardez bien à l’esprit que toutes les nodes du Cluster ont accès aux même ressources qui sont décrites et stockées par la node “Master”. Ce type d’architecture permet de fournir des services disposant d’une très haute disponibiliité.