Vous trouverez un aperçu de Kubernetes ici
Etapes d’implémentation
Mon architecture :
- 1 serveur de stockage des fichiers
- 1 serveur de base de données
- cluster applicatif Kubernetes (1 Master/2 workers). Les raisons d’isoler le stockage de données ? beaucoup de personnes le conseille afin de simplifier l’administration de l’ensemble. Les données étant le coeur du problème, elle doivent être sauvegardées fréquemment, surveillées, protégées et faciles à restaurer.
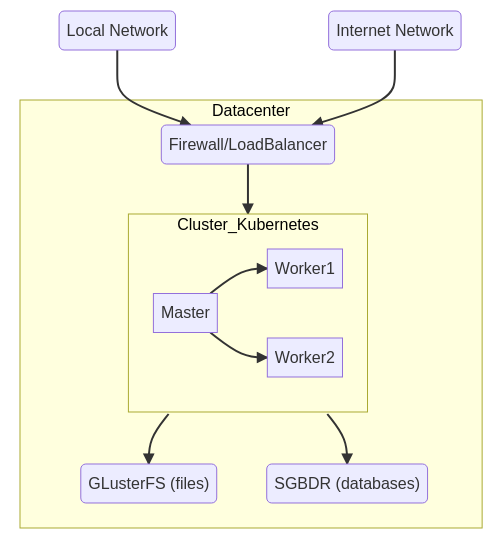
- Création d’un serveur de stockage Glusterfs
- Création d’un serveur de bases de données Posgresql/MongoDB (arm64)
- Installation d’un cluster Kubernetes
- Sauvegarde/Restauration ETCD
- Migration de nextcloud
- Créer et accéder à votre registry Docker Privée
- Chaîne CI/CD (drone)
- Installation Healthchecks
- Installation Matrix
- Installation SonarQube
- Migration BackupPC
- Migration hébergements sites web - support PHP7
- Migration Awstats
- Migration Swagger
- Exposer les services du cluster K8s
- Surveillance du Datacenter (Prometheus/Grafana)