“Kubernetes” dont l’acronyme est “K8s”, est un orchestrateur de conteneurs pour “Docker” (mais pas seulement). “Docker”, c’est quoi ? “Docker” permet de créer des conteneurs à partir d’une image, je ne rentrerai pas dans le détail ici, le web regorge de documentations à ce sujet. “Kubernetes” manipule “Docker”, donc “Kubernetes” seul ne sert à rien, tandis que “Docker” fonctionne parfaitement de manière autonome.
Images et conteneurs “Docker”
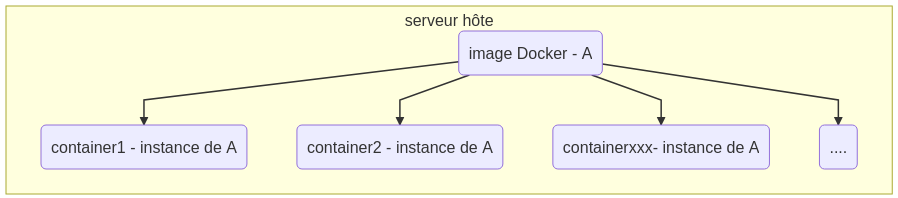
Une “image Docker” contient une application avec toutes ses dépendances logicielles. Un conteneur est une instance de cette image. En comparaison avec le programmation objet, une image est une “classe”, un conteneur est un objet manipulable
Je peux par conséquent, et ce, en limite des ressources du serveur hôte, démarrer autant d’instances (conteneurs) d’une image que je veux sur un serveur hôte.
Pourquoi utiliser “Docker” ?
Il existe plusieurs raisons à cela, mais en production, ce qui nous interresse avant tout : faciliter les déploiements…
Prenons cet exemple, je souhaite installer un serveur web de type “Apache”, au choix :
-
Je prend un serveur virtuel (VM) ou un serveur physique (bare metal), de type “Linux Debian” et j’installe “Apache” avec la commande :
apt-get -y install apache2. Le service est installé sur le serveur et directement accessible. Si veux ajouter un autre service “Apache2”, çà ce complique : comment installer deux services “Apache2”, les faire écouter sur deux ports différents… Cette opération nécessite du temps et demande une bonne maîtrise en terme d’administration système (sysadmin). -
L’autre solution consiste à utiliser “Docker”. Je vais démarrer deux conteneurs à partir de la seule image “Apache2”. Je n’ai aucune configuration à changer, les deux écouteront sur le port 80, mais dans leur zone d’exécution respective (notion d’isolation). Pour exposer ces deux services, j’aurais toujours besoins de deux ports (80 et 8080) sur le serveur “hôte”. Il va suffir d’indiquer à “Docker” de “router” le port 80 du serveur hôte vers le port 80 du premier conteneur, et le port 8080 du serveur hôte vers le port 80 du deuxième conteneur. (80->80 et 8080->80).

Les processus lancés à partir de “Docker” n’ont pas connaissance de l’hôte ni des autres conteneurs, ce processus tourne dans une “cage” (jail) complètement isolée du reste du système. “Docker” implémente donc un système de communication entre le serveur hôte et un conteneur, mais aussi un système de communication permettant de faire communiquer les conteneurs entre eux.
Utilisation de “Docker”
Là encore je ne rentre pas le détail, d’autres personnes ont écrit des bouquins entiers sur “Docker”, ce qui m’interresse c’est :
- Son installation sur un serveur
- Récupérer ou fabriquer des images
- Gérer des conteneurs (démarrer, stopper, ajouter, supprimer…)
- Exposer (réseau) les conteneurs pour pouvoir être utilisés sur le réseau local, internet…
- Accéder à des ressources de stockage, des base de données,… qui peuvent également être “contenérisées”.
“Kubernetes”
Une fois “Docker” appréhendé, vous vous rendez vite compte, surtout si vous opérez une mise à l’échelle (scalability), que cela devient “très, très, très compliqué” à gérer. C’est pourquoi le “sysadmin” a besoin d’un orchestrateur. Il s’agit d’une couche supérieure à “Docker” qui permet de gérer plus facilement l’ensemble des conteneurs nécessaires en production.
Alors “facilement” n’est pas le bon terme, car “Kubernetes” : C’est compliqué…
Gardez bien à l’esprit : “Kubernetes” est dessiné pour les fournisseurs de “Cloud” (Cloud providers) tels Ovh, Hetzner, Google, Amazon, Azure,…
Mais quand tout fonctionne, la gestion des conteneurs devient… beaucoup plus simple. On n’a pas à chercher sur quel serveur est installé tel conteneur, “Kubernetes” se charge d’équilibrer la demande. “Kubernetes” permet aussi de stocker la configuration des conteneurs dans un seul endroit (configmap), de centraliser les espaces de stockage persistents et bien plus.
Par exemple je dispose d’une image “Docker” applicative, je créer sa configuration et la stocke dans une entrée de “configmap”, je crée ensuite une configuration “Kubernetes” qui indique le nom de l’image “Docker” à utiliser, l’entrée “configmap” et je déploie avec “Kubernetes”. La mise à l’échelle ? C’est une seule commande, “Kubernetes” se charge du reste.
Ajouter une application, c’est tout d’abord la décrire : liste des conteneurs nécessaires, ses ressources… On parlera de “deployment”. Une fois l’application démarrée, la notion de “Pod” sera évoquée.
Un Pod est une unité applicative (démarrée) pour “Kubernetes”, qui ne connait pas directement la notion de conteneur. Garder bien à l’esprit : Un conteneur est obligatoirement embarqué dans un “pod”, un pod peut intégrer plusieurs conteneurs. Ceci permet de faciliter la communication entre les conteneurs contenus dans un pod, tous les conteneurs peuvent communiquer sur l’adresse “localhost (127.0.0.1)” du “pod”.