
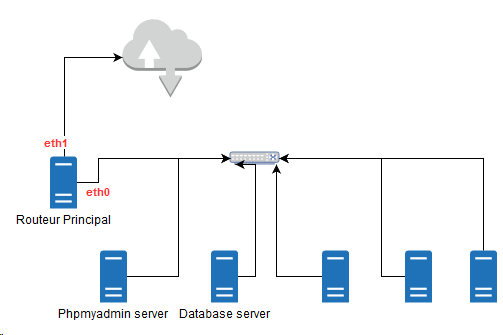
Topologie du réseau
Description du cas
- Opération réalisée sur un Mini-Datacenter MytinyDC (Raspberry PI et Rock64).
- Débit du réseau interne Datacenter : 100 Mbps soit un débit max théorique de 12.5 Mo/s
- Type de monitoring : “Prometheus” - “Grafana” - “Prometheus Alert”.
- L’attaque est menée sur le réseau du Datacenter.
- Fuite de données provoquée par un export de la base de données “ossec” au travers de l’application Phpmyadmin (Phpmyadmin server). Cette documentation ne couvre pas d’autres types de fuites.
- Le volume du dump “Mariadb” est d’environ 100 Mo.
- La base de données est entreposée sur le serveur “Database server”
- La règle initiale de détection (basique) : relève de la moyenne “rate()” glissante du débit de sortie de la carte Ethernet du serveur “Database server”, estimation d’une constante correspond à la limite à ne pas dépasser, ici** 2800 kb/s**.
- Création d’une règle d’alerte générique spécifique à ce cas, pour “Prometheus Alert” et indépendante de l’historique des données de monitoring.
- Retrouver la destination de sortie des données en utilisant **Grafana **et les données de monitoring disponibles.
- Création d’un dashboard (Grafana), permettant la répétition.
Etape 1
L’évènement provocateur sera l’export d’une base “MariaDB” (ossec dans notre cas) via l’application **phpmyadmin **qui est située sur le serveur “Phpmyadmin server”. Le service “MariaDB” est hébergé sur le serveur “Database server”. Le hacker va se connecter à **phpmyadmin **et utiliser la fonction “export” de cette application et récupérer le fichier des données exportées. Tout l’opération se déroule au travers du réseau du Datacenter.
Extraction des données par le réseau
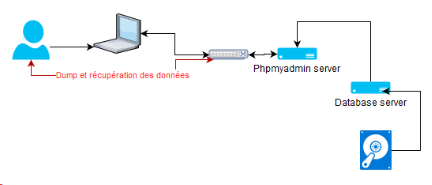
La reproduction de ce cas est simple. Le hacker a eu accès à l’application **phpmyadmin **, et à demandé l’export d’une base de donnée. Les informations disponibles :
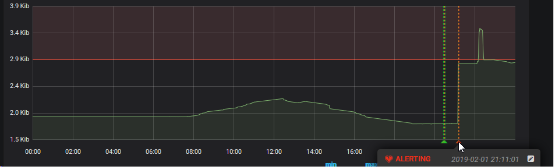
Ce graphique nous montre l’heure de l’alerte. Cette alerte est définie par un contrôle très basique du débit moyen glissant (fonction “rate()”), de la connexion Ethernet du serveur “Database server”, le seuil à ce moment était de 2800 kb/s. L’alerte est déclenchée à 21h11.
Voyons coté** Read I/O Disk** de ce serveur, sur la même période (sonde Prometheus : node_disk_read_bytes_total)
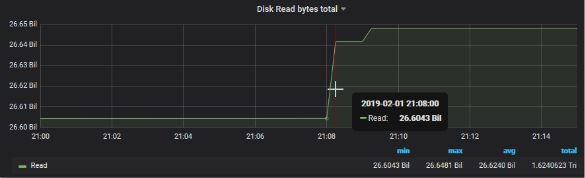
On peut constater une élévation soudaine de la courbe de lecture sur le disque dur
Coté** Write I/O Disk** de ce serveur, sur la même période (
sonde Prometheus : node_disk_written_bytes_total)
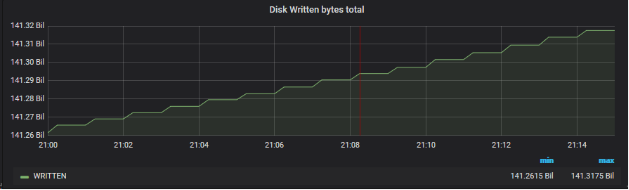
Rien de flagrant, le dump est effectué par le réseau.
Coté réseau :

Si des paquets réseaux sont sorties de ce serveur, ils ont forcément une destination (IN pour la device qui la reçu). Cela peut être une machine du réseau, ou bien, une machine de l’extérieur, notre Datacenter est relié à l’internet. Dans le cas ou nous ne trouverons pas de correspondance, ceci pourrait dire que le Hacker s’est connecté avec une device directement sur le réseau du Datacenter.
Analyse du trafic réseau IN des cartes réseaux (parc complet)
Ce graphique montre le débit moyen flottant des flux d’entrées sur les cartes réseaux du parc, non compris notre serveur “Database server”. Je prend un débit moyen car les débits en bits (graphique AB, plus bas), lissés entre les différents serveurs du Datacenter ne montrent pas de pics (lié au lissage de l’échelle effectué par Grafana).
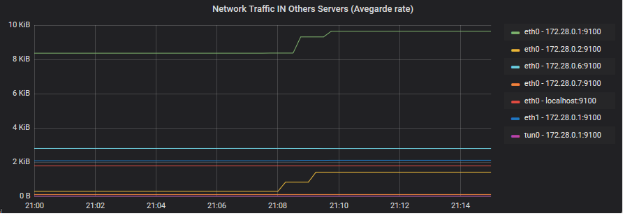
On voit nettement ici une correspondance sur les machine 172.28.0.1 et 172.28.0.2 (eth0 pour les deux). Les interfaces correspondent à des “devices” connectées au réseau du Datacenter. 172.28.0.2 est notre serveur “Phpmyadmin server”, 172.28.0.1 est notre serveur “Routeur principal”. On a aussi une lègère élévation sur eth1 de 172.28.0.1.
Zoom des devices incriminées sur le graphique de volumétrie brute (graphique AB)
eth0 - 172.28.0.1:9100
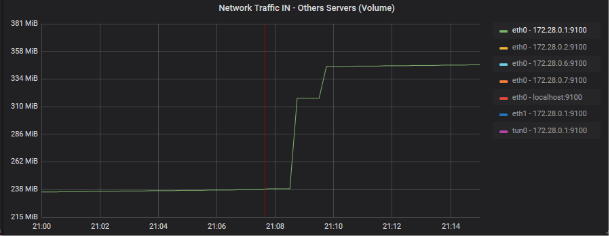
eth0 - 172.28.0.2:9100
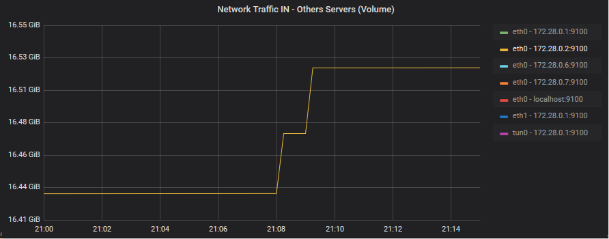
eth1 - 172.28.0.1:9100
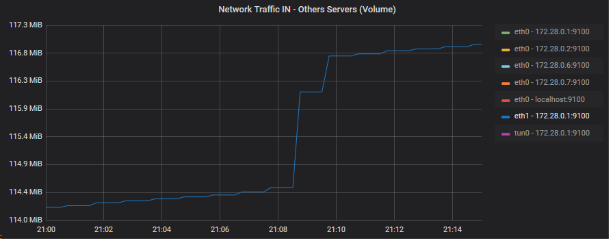
Je vais donc regarder le trafic OUT de cette dernière device, du fait qu’il s’agit du routeur principal du Datacenter :
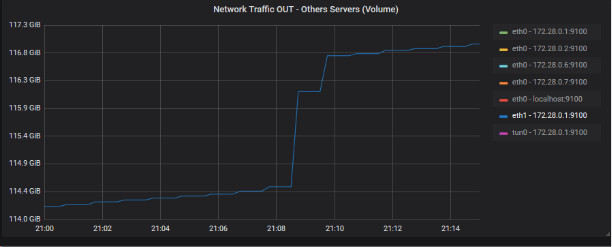
Le volume de sortie est assez important pour dégager une corrélation entre ce dernier et le volume de la fuite (approx 100 Mo). Résumons le scénario possible par un petit dessin
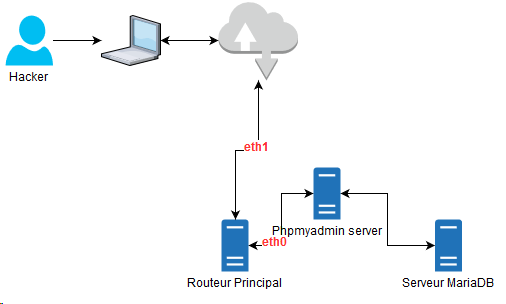
Nous avons maintenant établis le scénario de l’attaque, les premières questions/réponses :
| **Questions** | **Réponses** |
| Comment le **hacker **a-t-il trouvé l'exposition du **service phpmyadmin** ? | Le service haproxy, installé sur le routeur expose l'url : https://phpmyadmin.[nom de domaine], vérifier la sécurité du DNS qui peut offrir la possibilité d'un dump complet de la base des services du domaine principal |
| Comment le **hacker **a-t-il pu se connecter au **routeur Principal** ? | Par le service "phpmyadmin" au travers de son exposition offerte par "haproxy" qui écoute sans filtrages sur le port 443 (https) du routeur principal. |
| Quel type d'information dispose le hacker ? | Introspection des logs "apache2". C'est ce service qui fournit Phpmyadmin (alentours de 21h00) - voir le chapitre suivant |
| Et forcément, qui est le Hacker ? | voir le chapitre suivant |
Introspection log “apache2” sur serveur phpmyadmin
Commande utilisée :
grep -E "01/Feb/2019:21.*phpmyadmin.*export" access.log
Je récupère 4 lignes :
| 172.28.0.1 - - [01/Feb/2019:21:07:23 +0530] "GET /phpmyadmin/db_export.php?db=ossec&.... HTTP/1.1" 200 16013 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0" |
| 172.28.0.1 - - [01/Feb/2019:21:07:25 +0530] "GET /phpmyadmin/js/get_scripts.js.php?scripts%5B%5D=export.js.... HTTP/1.1" 200 6070 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0" |
| 172.28.0.1 - - [01/Feb/2019:21:12:40 +0530] "GET /phpmyadmin/export.php?ajax_request=true....1 HTTP/1.1" 200 2378 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0" |
| 172.28.0.1 - - [01/Feb/2019:21:36:37 +0530] "GET /phpmyadmin/db_export.php?db=ossec.... HTTP/1.1" 200 4380 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0" |
On peut déjà remarquer un premier problème : l’adresse IP du demandeur, est celle du routeur Prinicipal, où est disposé le service “haproxy”. Le serveur apache n’est pas bien configuré, il devrait présenter l’adresse réelle du demandeur et nous faire ainsi gagner du temps lors de cette introspection.
Le format standard de log apache2 est :
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
qu’il faut remplace par :
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
Le champs “X-Forwarded-For” est envoyé par haproxy.
Maintenant détectons les bases de données récupérées par le Hacker : on peut voir dans la première ligne :
db_export.php?db=ossec...
Modifions l’expression régulière de notre commande système :
grep -E "01/Feb/2019:21.*phpmyadmin.*export.*db=" access.log
A ce stade nous pouvons d’ores et déjà dire que le hacker n’a intercepté qu’une seule base de données dont le nom est “ossec”. Le responsable sécurité devra évaluer la pertinence des données interceptées par le hacker. On peut déjà dire qu’il dispose de tout le schéma de l’infrasctructure avec des login, sans mot de passe, etc… Les logs apache2 ne nous donnent pas le login de connexion du hacker, mais on peut voir qu’il s’est connecté directement, il connaissait donc le mot de passe.
Introspection du log haproxy
Le nom de domaine est phpmyadmin.[xxx]
Commande système :
grep -E "Feb 1 21:07.*phpmyadmin.*export.*db=" /var/log/haproxy.log
Je retrouve bien les traces et les urls correspondantes à celles de phpmyadmin sauf que je dispose dans ces traces, de l’adresse IP originale et le port (192.168.1.3:62123) utilisées par le Hacker :
Feb 1 21:07:25 xxxx haproxy[20906]: **192.168.1.3:62123** [01/Feb/2019:21:07:23.7 95] 192.168.1.115:80http phpmyadmin.xxxxx /xxxxx 0/0/0/1466/1474 200 16013 - - --- - 7/3/0/1/0 0/0 "GET /phpmyadmin/db_export.php?db=ossec... 3835 HTTP/1.1"
Essayons de retrouver le volume de la fuite à l’aide des logs haproxy ?
Commande système :
grep -E "Feb 1 21:.*phpmyadmin.*POST.*export" /var/log/haproxy.log
Feb 1 21:08:49 xxxxx haproxy[20906]: 192.168.1.3:62123 [01/Feb/2019:21:07:38.437] 192.168.1.115:80http phpmyadmin.xxxx /xxxxx 0/0/1/512/70932 200 **106063666 **- - ---- 6/3/0/1/0 0/0 "POST /phpmyadmin/export.php HTTP/1.1"
La fuite de données concerne : 106063666 bits soit plus de 100Mo de données !!!
Amélioration de l’infrastructure à proposer
Il s’agit d’un cas très simple, avec un pic d’activité détectable sur mon infrastructure (100mo) :
- Il faut trouver une formule mathématique qui permette l’automatisation de la détection et non au travers d’une pré-analyse de trafic et d’une limite au moyen d’une constante comme je l’ai utilisé ici. Sur une journée et selon l’organisation, il y aura forcément des pics, qui seront des faux positifs, vous aurez de plus à gérer les week-end, jours fériés, etc… ou l’activité est restreinte, avec l’utilisation de cette méthode, certaines périodes ou le delta sera très large permettra plus facilement le vol de données. Pour observer les pic d’un quantité prédéfinie (100mo par exemple) j’ai choisi de calculer le volume réseaux de sortie par rapport au dernier point relevé par le monitoring et le volume des deux dernières minutes. Le débit théorique de mon réseau est de 100 Mbps soit 12.5 Mo sec. Je prendrai raisonnablement 80% de cette valeur soit 10 Mo/sec. En une minute, mon réseau peut donc “évaporer” 600Mo. Si le démarrage du download démarre 1 sec avant le scrap du monitoring, je n’aurai que 10Mo de fuite sur le dernier relevé, par contre sur le suivant, j’aurai bien mes 590Mo.
- Le delta entre la détection est l’alerte m’amène donc à 2 min pour les scraps, + 1 minute de latence concernant l’alerte “Prometheus Alert”, ce qui nous fait 3 mn. En 3 minutes pleines avec le débit de mon réseau, le Hacker peut subtiliser 1.8 Go de données ce qui est assez conséquent. La solution envisageable est donc d’augmenter le fréquence des scraps Prometheus. Ceci va avoir un impact sur les performances… D’autre part, est il vraisemblable que l’équipe agissent immédiatement en coupant le service et durant la poursuite du download ? bien évidemment que non. A moins d’avoir du personnel concentré 24/24 avec un bouton d’arrêt d’urgence disponible pour chacun des services disponibles dans le Datacenter.
- Construire un tableau de bord “Grafana” spécifique à ce type d’attaque.
Conclusion
Pour mener à bien cette étude de cas, il faut des outils de monitoring performants, avec des périodes de scrap bien ajustées.
Le service Prometheus me plaît beaucoup, très simple à installer d’une part, il fonctionne parfaitement même sur des unités Raspberry PI.
L’outils d’analyse Grafana est un excellent outils et d’une importance primordiale dans cette étude. Il est précis et dispose d’une fonction sans précédent : ajouter des graphes sur un dashboard et dans les paramètres de ce dernier : “Panel Option” - “Graph Tooltip” - selectionnez “Shared CrossHair” - Enrgistrez. Déplacez vous sur un graphique, une ligne verticale rouge se positionne sur tous les graphes du tableau de bord de la même période. Par conséquent si vous positionnez le curseur de votre souris sur le pic d’un graphe, cette fonction permet de faire ressortir immédiatement les pics constatés sur les autres graphiques.
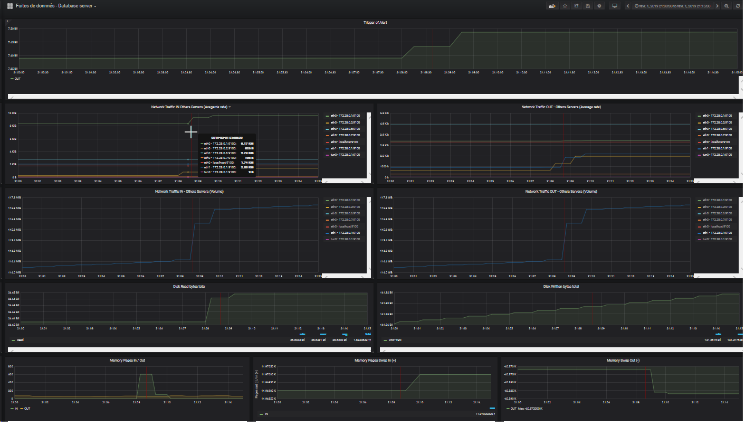
On voit bien que ce type d’attaque nécessite une détection et une contre mesure immédiate, quand bien même, il est évident que ce type de processus doit-être mis en place. Si vous n’avez pu empêcher la fuite, vous pourrez agir très rapidement en modifiant les paramétrages du Datacenter pour que ceci ne se répète pas.
Pour sécuriser un réseau face à ce type de fuites de données, il faut ( liste non exhaustive ) :
- Nous venons de le voir, disposer d’outils adaptés
- être conscient du volume qui peut “s’évaporer” en 3 minutes seulement
- être préparé afin d’évaluer rapidement l’étendue de la fuite
- disposer d’une documentation précise de votre infrastructure
- disposer d’une procédure permettant à des administrateurs systèmes d’opérer le plus rapidement possible (login/password || clé ssh pour permettra l’analyse des logs, etc….)
- disposer d’automates qui permettent de couper immédiatement des services.
- paramétrer correctement les services disponibles sur le réseau (apache2 dans mon cas)
- trouver une solution centralisée des logs pour tous les serveurs. Ceci évite aux administrateurs systèmes d’avoir à se connecter aux différents serveurs, mise en cause, pour analyser les logs. Un environnement centralisé permet d’aller beaucoup plus vite.
- Pour une infrastructure hébergeant des données critiques il faudra vraisemblablement penser à installer de l’intelligence artificielle, capable d’analyser en temps réels, les différents cas de votre organisation.
- Permettre un traçage des connexions au serveurs de base de données (login date/time).
- Revoir la politique d’accès à l’infrastructure (règle de firewall, délégation des droits, politique de gestion des mots de passe, etc..)
- être aussi conscient du travail considérable et nécessaire pour la mise en place d’un plan de surveillance des fuites de données.
Licence de ce document : Creative Commons (CC BY-NC-ND 4.0)
CETTE DOCUMENTATION EST LIVRÉE “EN L’ÉTAT”, SANS GARANTIE D’AUCUNE SORTE ET DISTRIBUÉE DANS UN BUT ÉDUCATIF EXCLUSIVEMENT. L’AUTEUR, CONTRIBUTEURS DE CETTE DOCUMENTATION OU ©MYTINYDC.COM NE SAURAIENT EN AUCUN CAS ÊTRE TENUS RESPONSABLES DES DOMMAGES DIRECTS OU INDIRECTS POUVANT RÉSULTER DE L’APPLICATION DES PROCÉDURES MISES EN ŒUVRE DANS CETTE DOCUMENTATION, OU DE LA MAUVAISE INTERPRÉTATION DE CE DOCUMENT.